**概述**
关于XGBoost 模型,此前论坛已有用户做了初步研究,如恶魔猎手的[《基于随机森林和XGBoost的多因子模型分析》](https://www.joinquant.com/view/community/detail/a8f0764b797e8545754e01a5e01eb8fd),借鉴了华泰证券林晓明先生的《人工智能选股系列研报》以及西安交大元老师量化小组[《支持向量机模型(SVM)在多因子选股模型领域的应用》](https://www.joinquant.com/view/community/detail/e335e464e3233b5623c7b30f495807ac?type=1)。
前期,我尝试利用上述文章中的代码训练模型并做了策略,发现XGBoost的二分类模型选股策略收益并不理想。于是尝试了使用XGBoost的多分类模型方式进行选股,由于多分类模型训练时间较长,在没有调参的情况下,目前初步得出的结论是,XGBoost的多分类模型有助于提高选股收益。且似乎分类越多,获取的超额收益越多(目前初步发现12分类超额收益 > 6分类超额收益 > 2类超额收益)
这次,我将因子获取、模型训练、回测策略的代码放上来,供大家参考,以便抛砖引玉,尝试更多的参数进行训练,获取更优的XGBoost模型应用于策略。
感谢 西安交大元老师量化小组 和 恶魔猎手,我的研究和策略大量使用了两位的代码及研究成果。
以下代码在Python3 的研究环境中使用
**导入可能会用到的库**
```
from jqdata import *
from jqlib.technical_analysis import *
from jqfactor import get_factor_values
from jqfactor import winsorize_med
from jqfactor import standardlize
from jqfactor import neutralize
import datetime
import pandas as pd
import numpy as np
from scipy import stats
import statsmodels.api as sm
from statsmodels import regression
from six import StringIO
from sklearn.decomposition import PCA
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from xgboost import XGBClassifier
from xgboost import Booster
from xgboost import DMatrix
from sklearn import metrics
import matplotlib.dates as mdates
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
import datetime
import pickle
```
**获取因子数据**
这里获取的因子与西安交大元老师量化小组《支持向量机模型(SVM)在多因子选股模型领域的应用》的因子一致,共66个因子。取数时间很长,两年的因子数据要跑几个小时,需要耐心等待。
```
#获取指定周期的日期列表 'W、M、Q'
def get_period_date(peroid,start_date, end_date):
#设定转换周期period_type 转换为周是'W',月'M',季度线'Q',五分钟'5min',12天'12D'
stock_data = get_price('000001.XSHE',start_date,end_date,'daily',fields=['close'])
#记录每个周期中最后一个交易日
stock_data['date']=stock_data.index
stock_date = stock_data.index
pydate_array = stock_date.to_pydatetime()
#进行转换,周线的每个变量都等于那一周中最后一个交易日的变量值
period_stock_data=stock_data.resample(peroid,how= 'last').dropna()
#print(period_stock_data)
period_stock_data.index =period_stock_data['date']
date=period_stock_data.index
pydate_array = date.to_pydatetime()
date_only_array = np.vectorize(lambda s: s.strftime('%Y-%m-%d'))(pydate_array )
date_only_series = pd.Series(date_only_array)
#print(date_only_series)
start_date = datetime.datetime.strptime(start_date, "%Y-%m-%d")
start_date=start_date-datetime.timedelta(days=1)
start_date = start_date.strftime("%Y-%m-%d")
date_list = date_only_series.values.tolist()
date_list.insert(0,start_date)
#print(date_list)
return date_list
#去除上市距beginDate不足3个月的股票
def delect_stop(stocks,beginDate,n=30*3):
stockList=[]
beginDate = datetime.datetime.strptime(beginDate, "%Y-%m-%d")
for stock in stocks:
start_date=get_security_info(stock).start_date
if start_date< (beginDate-datetime.timedelta(days=n)).date():
stockList.append(stock)
return stockList
#获取股票池
def get_stock(stockPool,begin_date):
if stockPool=='HS300':
stockList=get_index_stocks('000300.XSHG',begin_date)
elif stockPool=='ZZ500':
stockList=get_index_stocks('399905.XSHE',begin_date)
elif stockPool=='ZZ800':
stockList=get_index_stocks('399906.XSHE',begin_date)
elif stockPool=='CYBZ':
stockList=get_index_stocks('399006.XSHE',begin_date)
elif stockPool=='ZXBZ':
stockList=get_index_stocks('399005.XSHE',begin_date)
elif stockPool=='A':
stockList=get_index_stocks('000002.XSHG',begin_date)+get_index_stocks('399107.XSHE',begin_date)
#剔除ST股
st_data=get_extras('is_st',stockList, count = 1,end_date=begin_date)
stockList = [stock for stock in stockList if not st_data[stock][0]]
#剔除停牌、新股及退市股票
stockList=delect_stop(stockList,begin_date)
return stockList
# 辅助线性回归的函数
def linreg(X,Y,columns=3):
X=sm.add_constant(array(X))
Y=array(Y)
if len(Y)>1:
results = regression.linear_model.OLS(Y, X).fit()
return results.params
else:
return [float("nan")]*(columns+1)
#取股票对应行业
def get_industry_name(i_Constituent_Stocks, value):
return [k for k, v in i_Constituent_Stocks.items() if value in v]
#缺失值处理
def replace_nan_indu(factor_data,stockList,industry_code,date):
#把nan用行业平均值代替,依然会有nan,此时用所有股票平均值代替
i_Constituent_Stocks={}
data_temp=pd.DataFrame(index=industry_code,columns=factor_data.columns)
for i in industry_code:
temp = get_industry_stocks(i, date)
i_Constituent_Stocks[i] = list(set(temp).intersection(set(stockList)))
data_temp.loc[i]=mean(factor_data.loc[i_Constituent_Stocks[i],:])
for factor in data_temp.columns:
#行业缺失值用所有行业平均值代替
null_industry=list(data_temp.loc[pd.isnull(data_temp[factor]),factor].keys())
for i in null_industry:
data_temp.loc[i,factor]=mean(data_temp[factor])
null_stock=list(factor_data.loc[pd.isnull(factor_data[factor]),factor].keys())
for i in null_stock:
industry=get_industry_name(i_Constituent_Stocks, i)
if industry:
factor_data.loc[i,factor]=data_temp.loc[industry[0],factor]
else:
factor_data.loc[i,factor]=mean(factor_data[factor])
return factor_data
#数据预处理
def data_preprocessing(factor_data,stockList,industry_code,date):
#去极值
factor_data=winsorize_med(factor_data, scale=5, inf2nan=False,axis=0)
#缺失值处理
factor_data=replace_nan_indu(factor_data,stockList,industry_code,date)
#中性化处理
factor_data=neutralize(factor_data, how=['sw_l1', 'market_cap'], date=date, axis=0)
#标准化处理
factor_data=standardlize(factor_data,axis=0)
return factor_data
#获取时间为date的全部因子数据
def get_factor_data(stock,date):
data=pd.DataFrame(index=stock)
q = query(valuation,balance,cash_flow,income,indicator).filter(valuation.code.in_(stock))
df = get_fundamentals(q, date)
df['market_cap']=df['market_cap']*100000000
factor_data=get_factor_values(stock,['roe_ttm',
'roa_ttm',
'total_asset_turnover_rate',
'net_operate_cash_flow_ttm',
'net_profit_ttm',
'cash_to_current_liability',
'current_ratio',
'gross_income_ratio',
'non_recurring_gain_loss',
'operating_revenue_ttm',
'net_profit_growth_rate'
],end_date=date,count=1)
factor=pd.DataFrame(index=stock)
for i in factor_data.keys():
factor[i]=factor_data[i].iloc[0,:]
df.index = df['code']
del df['code'],df['id']
#合并得大表
df=pd.concat([df,factor],axis=1)
#净利润(TTM)/总市值
data['EP']=df['net_profit_ttm']/df['market_cap']
#净资产/总市值
data['BP']=1/df['pb_ratio']
#营业收入(TTM)/总市值
data['SP']=1/df['ps_ratio']
#净现金流(TTM)/总市值
data['NCFP']=1/df['pcf_ratio']
#经营性现金流(TTM)/总市值
data['OCFP']=df['net_operate_cash_flow_ttm']/df['market_cap']
#净利润(TTM)同比增长率/PE_TTM
data['G/PE']=df['net_profit_growth_rate']/df['pe_ratio']
#ROE_ttm
data['roe_ttm']=df['roe_ttm']
#ROE_YTD
data['roe_q']=df['roe']
#ROA_ttm
data['roa_ttm']=df['roa_ttm']
#ROA_YTD
data['roa_q']=df['roa']
#毛利率TTM
data['grossprofitmargin_ttm']=df['gross_income_ratio']
#毛利率YTD
data['grossprofitmargin_q']=df['gross_profit_margin']
#扣除非经常性损益后净利润率YTD
data['profitmargin_q']=df['adjusted_profit']/df['operating_revenue']
#资产周转率TTM
data['assetturnover_ttm']=df['total_asset_turnover_rate']
#资产周转率YTD 营业收入/总资产
data['assetturnover_q']=df['operating_revenue']/df['total_assets']
#经营性现金流/净利润TTM
data['operationcashflowratio_ttm']=df['net_operate_cash_flow_ttm']/df['net_profit_ttm']
#经营性现金流/净利润YTD
data['operationcashflowratio_q']=df['net_operate_cash_flow']/df['net_profit']
#净资产
df['net_assets']=df['total_assets']-df['total_liability']
#总资产/净资产
data['financial_leverage']=df['total_assets']/df['net_assets']
#非流动负债/净资产
data['debtequityratio']=df['total_non_current_liability']/df['net_assets']
#现金比率=(货币资金+有价证券)÷流动负债
data['cashratio']=df['cash_to_current_liability']
#流动比率=流动资产/流动负债*100%
data['currentratio']=df['current_ratio']
#总市值取对数
data['ln_capital']=np.log(df['market_cap'])
#TTM所需时间
his_date = [pd.to_datetime(date) - datetime.timedelta(90*i) for i in range(0, 4)]
tmp = pd.DataFrame()
tmp['code']=stock
for i in his_date:
tmp_adjusted_dividend = get_fundamentals(query(indicator.code, indicator.adjusted_profit, \
cash_flow.dividend_interest_payment).
filter(indicator.code.in_(stock)), date = i)
tmp=pd.merge(tmp,tmp_adjusted_dividend,how='outer',on='code')
tmp=tmp.rename(columns={'adjusted_profit':'adjusted_profit'+str(i.month), \
'dividend_interest_payment':'dividend_interest_payment'+str(i.month)})
tmp=tmp.set_index('code')
tmp_columns=tmp.columns.values.tolist()
tmp_adjusted=sum(tmp[[i for i in tmp_columns if 'adjusted_profit'in i ]],1)
tmp_dividend=sum(tmp[[i for i in tmp_columns if 'dividend_interest_payment'in i ]],1)
#扣除非经常性损益后净利润(TTM)/总市值
data['EPcut']=tmp_adjusted/df['market_cap']
#近12个月现金红利(按除息日计)/总市值
data['DP']=tmp_dividend/df['market_cap']
#扣除非经常性损益后净利润率TTM
data['profitmargin_ttm']=tmp_adjusted/df['operating_revenue_ttm']
#营业收入(YTD)同比增长率
#_x现在 _y前一年
his_date = pd.to_datetime(date) - datetime.timedelta(365)
name=['operating_revenue','net_profit','net_operate_cash_flow','roe']
temp_data=df[name]
his_temp_data = get_fundamentals(query(valuation.code, income.operating_revenue,income.net_profit,\
cash_flow.net_operate_cash_flow,indicator.roe).
filter(valuation.code.in_(stock)), date = his_date)
his_temp_data=his_temp_data.set_index('code')
#重命名 his_temp_data last_year
for i in name:
his_temp_data=his_temp_data.rename(columns={i:i+'last_year'})
temp_data =pd.concat([temp_data,his_temp_data],axis=1)
#营业收入(YTD)同比增长率
data['sales_g_q']=temp_data['operating_revenue']/temp_data['operating_revenuelast_year']-1
#净利润(YTD)同比增长率
data['profit_g_q']=temp_data['net_profit']/temp_data['net_profitlast_year']-1
#经营性现金流(YTD)同比增长率
data['ocf_g_q']=temp_data['net_operate_cash_flow']/temp_data['net_operate_cash_flowlast_year']-1
#ROE(YTD)同比增长率
data['roe_g_q']=temp_data['roe']/temp_data['roelast_year']-1
#个股60个月收益与上证综指回归的截距项与BETA
stock_close=get_price(stock, count = 60*20+1, end_date=date, frequency='daily', fields=['close'])['close']
SZ_close=get_price('000001.XSHG', count = 60*20+1, end_date=date, frequency='daily', fields=['close'])['close']
stock_pchg=stock_close.pct_change().iloc[1:]
SZ_pchg=SZ_close.pct_change().iloc[1:]
beta=[]
stockalpha=[]
for i in stock:
temp_beta, temp_stockalpha = stats.linregress(SZ_pchg, stock_pchg[i])[:2]
beta.append(temp_beta)
stockalpha.append(temp_stockalpha)
#此处alpha beta为list
data['alpha']=stockalpha
data['beta']=beta
#动量
data['return_1m']=stock_close.iloc[-1]/stock_close.iloc[-20]-1
data['return_3m']=stock_close.iloc[-1]/stock_close.iloc[-60]-1
data['return_6m']=stock_close.iloc[-1]/stock_close.iloc[-120]-1
data['return_12m']=stock_close.iloc[-1]/stock_close.iloc[-240]-1
#取换手率数据
data_turnover_ratio=pd.DataFrame()
data_turnover_ratio['code']=stock
trade_days=list(get_trade_days(end_date=date, count=240*2))
for i in trade_days:
q = query(valuation.code,valuation.turnover_ratio).filter(valuation.code.in_(stock))
temp = get_fundamentals(q, i)
data_turnover_ratio=pd.merge(data_turnover_ratio, temp,how='left',on='code')
data_turnover_ratio=data_turnover_ratio.rename(columns={'turnover_ratio':i})
data_turnover_ratio=data_turnover_ratio.set_index('code').T
#个股个股最近N个月内用每日换手率乘以每日收益率求算术平均值
data['wgt_return_1m']=mean(stock_pchg.iloc[-20:]*data_turnover_ratio.iloc[-20:])
data['wgt_return_3m']=mean(stock_pchg.iloc[-60:]*data_turnover_ratio.iloc[-60:])
data['wgt_return_6m']=mean(stock_pchg.iloc[-120:]*data_turnover_ratio.iloc[-120:])
data['wgt_return_12m']=mean(stock_pchg.iloc[-240:]*data_turnover_ratio.iloc[-240:])
#个股个股最近N个月内用每日换手率乘以函数exp(-x_i/N/4)再乘以每日收益率求算术平均值
temp_data=pd.DataFrame(index=data_turnover_ratio[-240:].index,columns=stock)
temp=[]
for i in range(240):
if i/20< 1:
temp.append(exp(-i/1/4))
elif i/20< 3:
temp.append(exp(-i/3/4))
elif i/20< 6:
temp.append(exp(-i/6/4))
elif i/20< 12:
temp.append(exp(-i/12/4))
temp.reverse()
for i in stock:
temp_data[i]=temp
data['exp_wgt_return_1m']=mean(stock_pchg.iloc[-20:]*temp_data.iloc[-20:]*data_turnover_ratio.iloc[-20:])
data['exp_wgt_return_3m']=mean(stock_pchg.iloc[-60:]*temp_data.iloc[-60:]*data_turnover_ratio.iloc[-60:])
data['exp_wgt_return_6m']=mean(stock_pchg.iloc[-120:]*temp_data.iloc[-120:]*data_turnover_ratio.iloc[-120:])
data['exp_wgt_return_12m']=mean(stock_pchg.iloc[-240:]*temp_data.iloc[-240:]*data_turnover_ratio.iloc[-240:])
#特异波动率
#获取FF三因子残差数据
LoS=len(stock)
S=df.sort_values(by = 'market_cap')[:int(LoS/3)].index
B=df.sort_values(by = 'market_cap')[int(LoS-LoS/3):].index
df['BTM']=df['total_owner_equities']/df['market_cap']
L=df.sort_values(by = 'BTM')[:int(LoS/3)].index
H=df.sort_values(by = 'BTM')[int(LoS-LoS/3):].index
df_temp=stock_pchg.iloc[-240:]
#求因子的值
SMB=sum(df_temp[S].T)/len(S)-sum(df_temp[B].T)/len(B)
HMI=sum(df_temp[H].T)/len(H)-sum(df_temp[L].T)/len(L)
#用中证800作为大盘基准
dp=get_price('000300.XSHG',count=12*20+1,end_date=date,frequency='daily', fields=['close'])['close']
RM=dp.pct_change().iloc[1:]-0.04/252
#将因子们计算好并且放好
X=pd.DataFrame({"RM":RM,"SMB":SMB,"HMI":HMI})
resd=pd.DataFrame()
for i in stock:
temp=df_temp[i]-0.04/252
t_r=linreg(X,temp)
resd[i]=list(temp-(t_r[0]+X.iloc[:,0]*t_r[1]+X.iloc[:,1]*t_r[2]+X.iloc[:,2]*t_r[3]))
data['std_FF3factor_1m']=resd[-1*20:].std()
data['std_FF3factor_3m']=resd[-3*20:].std()
data['std_FF3factor_6m']=resd[-6*20:].std()
data['std_FF3factor_12m']=resd[-12*20:].std()
#波动率
data['std_1m']=stock_pchg.iloc[-20:].std()
data['std_3m']=stock_pchg.iloc[-60:].std()
data['std_6m']=stock_pchg.iloc[-120:].std()
data['std_12m']=stock_pchg.iloc[-240:].std()
#股价
data['ln_price']=np.log(stock_close.iloc[-1])
#换手率
data['turn_1m']=mean(data_turnover_ratio.iloc[-20:])
data['turn_3m']=mean(data_turnover_ratio.iloc[-60:])
data['turn_6m']=mean(data_turnover_ratio.iloc[-120:])
data['turn_12m']=mean(data_turnover_ratio.iloc[-240:])
data['bias_turn_1m']=mean(data_turnover_ratio.iloc[-20:])/mean(data_turnover_ratio)-1
data['bias_turn_3m']=mean(data_turnover_ratio.iloc[-60:])/mean(data_turnover_ratio)-1
data['bias_turn_6m']=mean(data_turnover_ratio.iloc[-120:])/mean(data_turnover_ratio)-1
data['bias_turn_12m']=mean(data_turnover_ratio.iloc[-240:])/mean(data_turnover_ratio)-1
#技术指标
data['PSY']=pd.Series(PSY(stock, date, timeperiod=20))
data['RSI']=pd.Series(RSI(stock, date, N1=20))
data['BIAS']=pd.Series(BIAS(stock,date, N1=20)[0])
dif,dea,macd=MACD(stock, date, SHORT = 10, LONG = 30, MID = 15)
data['DIF']=pd.Series(dif)
data['DEA']=pd.Series(dea)
data['MACD']=pd.Series(macd)
return data
peroid = 'D' #设置按日为周期获取数据,数据量会比较大,但便于之后选取选取用于模型训练
start_date = '2017-01-01' #获取因子数据的开始日期,自行设定
end_date = '2018-12-31' #获取因子数据的结束日期,自行设定
industry_old_code = ['801010','801020','801030','801040','801050','801080','801110','801120','801130','801140','801150',\
'801160','801170','801180','801200','801210','801230']
industry_new_code = ['801010','801020','801030','801040','801050','801080','801110','801120','801130','801140','801150',\
'801160','801170','801180','801200','801210','801230','801710','801720','801730','801740','801750',\
'801760','801770','801780','801790','801880','801890']
dateList = get_period_date(peroid,start_date, end_date)
factor_origl_data = {}
factor_solve_data = {}
starttime = datetime.datetime.now()
for date in dateList:
#获取行业因子数据
print ('获取数据的日期:',date,end='')
if datetime.datetime.strptime(date,"%Y-%m-%d").date()< datetime.date(2014,2,21):
industry_code=industry_old_code
else:
industry_code=industry_new_code
stockList=get_stock('ZZ800',date) #获取的是中证800成分股因子数据
factor_origl_data[date] = get_factor_data(stockList,date)
factor_solve_data[date] = data_preprocessing(factor_origl_data[date],stockList,industry_code,date)
endtime = datetime.datetime.now()
print ('取数运行时长:',int((endtime - starttime).seconds/60),'分钟')
```
**保存获取的因子数据**
```
content = pd.Panel(data=factor_solve_data)
content.to_pickle("factor_solve_data.pkl") #保存因子数据字典,以便以后用于模型训练
```
**读取保存好的因子数据**
这里在选取数据的同时,对于因子数据打了标签,首先按照股票的5天收益率排序,然后分成12组,每组为一类打标签,其中标签为0的收益最高,标签为11的收益最低。
```
pkl_file_read = pd.read_pickle("factor_solve_data.pkl")
factor_data = {}
for item in pkl_file_read.items:
factor_data[item] = pkl_file_read[item]
factor_data
```
**选取训练集的因子数据**
```
peroid='D'
start_date='2017-01-01'
end_date='2018-12-31'
industry_old_code=['801010','801020','801030','801040','801050','801080','801110','801120','801130','801140','801150',\
'801160','801170','801180','801200','801210','801230']
industry_new_code=['801010','801020','801030','801040','801050','801080','801110','801120','801130','801140','801150',\
'801160','801170','801180','801200','801210','801230','801710','801720','801730','801740','801750',\
'801760','801770','801780','801790','801880','801890']
dateList=get_period_date(peroid,start_date, end_date)
# 训练集数据
train_data=pd.DataFrame()
for date in dateList[:int(len(dateList)*4/5)]: #取前五分之四的数据为训练集,可自行修改
traindf=factor_data[date]
stockList=list(traindf.index)
#取收益率数据
if dateList.index(date)+5 >=len(dateList):
break
print(date,dateList[dateList.index(date)+5],end='')
data_close=get_price(stockList,date,dateList[dateList.index(date)+5],'1d','close')['close']
traindf['pchg']=data_close.iloc[-1]/data_close.iloc[0]-1
#剔除空值
traindf=traindf.dropna()
traindf=traindf.sort_values(by='pchg')
traindf['labetemp']=traindf['pchg'].rank(ascending=0,method='dense')
length = len(list(traindf['labetemp']))
traindf['label']=list(traindf['labetemp'].apply(lambda x:0 if x < = length/12
else(1 if x >length/12 and x < = length*2/12
else(2 if x >length*2/12 and x < = length*3/12
else(3 if x>length*3/12 and x < = length*4/12
else(4 if x>length*4/12and x < = length*5/12
else(5 if x>length*5/12and x < = length*6/12
else(6 if x>length*6/12and x < = length*7/12
else(7 if x>length*7/12and x < = length*8/12
else(8 if x>length*8/12and x < = length*9/12
else(9 if x>length*9/12and x < = length*10/12
else(10 if x>length*10/12and x < = length*11/12
else 11))))))))))
))
#traindf=traindf.iloc[:round(len(traindf['pchg'])/10*3),:].append(traindf.iloc[round(len(traindf['pchg'])/10*7):,:])
if train_data.empty:
train_data=traindf
else:
train_data=train_data.append(traindf)
```
**应用XGBoost对打好标签的因子数据训练**
```
# 获取特征及标签
train_target=train_data['label']
train_feature=train_data.copy()
del train_feature['pchg']
del train_feature['label']
del train_feature['labetemp']
# 获取模型
clf = XGBClassifier(n_estimators=800, max_depth=7,subsample=0.9,random_state=0 , objective ='multi:softprob', num_class = 12)
#模型的参数可以调,由于训练时间很长,我这里只是简单粗暴地设置了几个参数,不一定准确,这块希望可以抛砖引玉,大家多测试下,看看其他参数的模型训练效果,希望大家可以在帖子里分享调参结果,非常感谢!
# 模型训练
starttime = datetime.datetime.now()
print ('开始训练模型')
clf.fit(np.array(train_feature),np.array(train_target))
endtime = datetime.datetime.now()
print ('模型运行时长:',int((endtime - starttime).seconds/60),'分钟')
```
**保存训练好的模型和读取模型**
```
clf.save_model('xgb_factors.model') #保存训练好的模型
clf = Booster(model_file='xgb_factors.model')
#在研究中读取训练好的模型,如果在策略中需要读取模型,需要使用其他代码,详见策略代码
```
**XGBoost多因子选股策略**
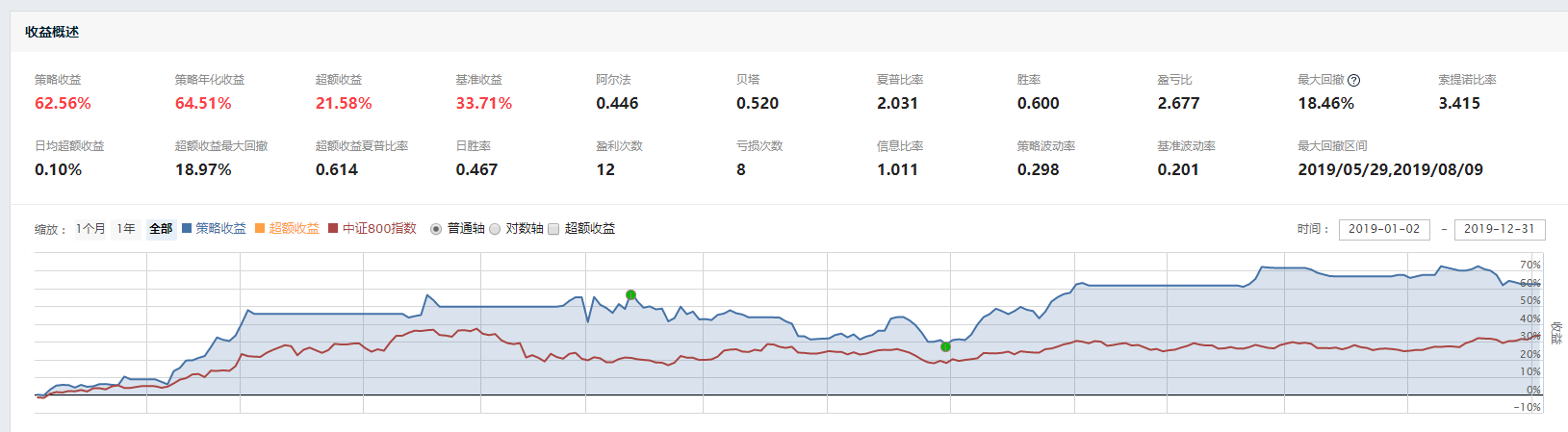
我这次做的回测,是使用多分类XGBoost模型对2017年至2018年中证800成份股因子数据做的训练,训练时一共分为12类。
策略是每5天交易一次,每次持有中证800成份股中第一类(5天收益率最高的一类)预测概率最高的前20只股票,策略回测的交易时间是2019年,应该不存在未来函数。
训练好的模型已上传百度网盘,大家可以下载上传到研究环境根目录来使用。
链接: https://pan.baidu.com/s/1adt0AnaPSXZGNqa3P2VPfA
提取码: bqdn
**策略可优化方向**
1、增加获取因子数据时长。目前只是获取两年的数据,可以考虑获取3年或更长时间的数据来做训练。
2、增加更多有效因子。这个需要可添加其他因子来做测试。
3、尝试更多的分类。目前的多分类模型选择的是12类,可以尝试不同的分类。
4、模型参数调优。尝试更多的参数来对模型做优化。
5、交易周期优化。目前尝试的是5天交易一次,还可以尝试不同的交易周期,同样,打标签的收益率周期也可以优化。
6、尝试不同的选股范围。这次策略使用的是中证800指数成份股,可以扩大和调整这个选股范围。
7、定期滚动训练模型。以便模型适应新的状况。
**感谢**
由于个人水平有限,研究和策略中如存在错误和不足的地方,请各位批评指正!谢谢各位!
**2020年2月12日更新:**
策略依然是使用17年至18年数据训练好的模型(已在帖子中做了网盘共享),每5天交易一次,每次等权持有中证800成份股中第一类(5天收益率最高的一类)预测概率最高的股票,但是这次要求预测的概率需大于0.5,每只股票的仓位是:1/持股总数。如果所有股票第一类的预测概率都不大于0.5,则空仓。
感觉收益好了不少,貌似还自带择时属性。
由于代码改动不多,这次修改只放上回测的结果,不放上代码了。